Anomalies & Recommendations
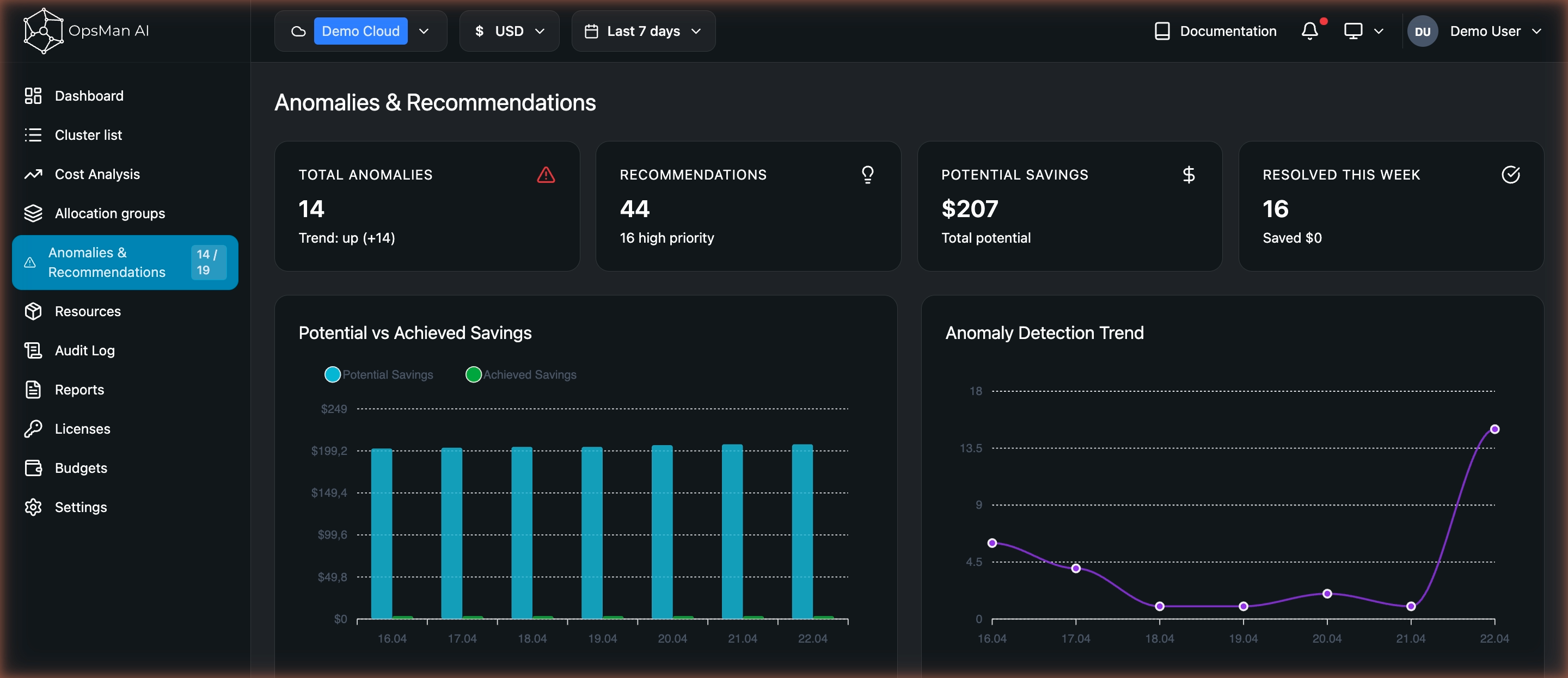
Страница Anomalies & Recommendations (пункт меню Аномалии и рекомендации с живым бейджем активных счётчиков) объединяет на одном экране два таба:
- Recommendations — конкретные действия по оптимизации расходов.
- Anomalies — отклонения в работе инфраструктуры и расходах, найденные ежедневной автоматической детекцией.
Оба таба используют общую шапку: четыре KPI-карточки и два графика.
Обзор — KPI и графики
Заголовок раздела «Обзор — KPI и графики»Верхний ряд — 4 KPI
Заголовок раздела «Верхний ряд — 4 KPI»| Блок | Смысл |
|---|---|
| Total Anomalies | Число активных аномалий + тренд (up (+14) за период) |
| Recommendations | Число рекомендаций + сколько с high priority |
| Potential Savings | Совокупный потенциал экономии |
| Resolved This Week | Сколько решено за неделю и сколько это сохранило |
Графики
Заголовок раздела «Графики»- Potential vs Achieved Savings — столбцы: синие — потенциал, зелёные — уже реализовано.
- Anomaly Detection Trend — линия числа новых аномалий за период.
Таб Recommendations
Заголовок раздела «Таб Recommendations»В отличие от аномалий, которые описывают инцидент, рекомендации предлагают конкретное действие.
1. Quick wins
Заголовок раздела «1. Quick wins»Рекомендации, которые обычно можно выполнить сразу, без переговоров с поставщиком.
Под-табы:
- Low utilization — ресурс работает, но CPU или память стабильно ниже 40%. Предложение — сменить тип / размер (right-sizing).
- Unmounted disk — диск не привязан к ни одной VM → предложение удалить.
- Unused S3 bucket — bucket без активности → предложение удалить.
- Old snapshot — snapshot старше 90 дней → предложение удалить.
Таблица:
| Колонка | Смысл |
|---|---|
| Resource | Имя + облако/кластер |
| Service | Тип сервиса (instance, database-postgresql, …) |
| Priority | high / medium / low |
| CPU | Текущие → рекомендуемые vCPU |
| Memory | Текущая → рекомендуемая память |
| Potential savings | Экономия в месяц в выбранной валюте |
Справа в строке — иконка «скрыть» (аналогично Anomalies).
2. Long-term optimization — CVoS
Заголовок раздела «2. Long-term optimization — CVoS»Committed Volume of Services — обязательство перед облачным провайдером на 6 или 12 месяцев в обмен на скидку.
Карточки по типам ресурсов:
| Сценарий | Пример для Managed PostgreSQL |
|---|---|
| Current | $238/mo |
| 6 months | $202/mo (-15%) |
| 1 year | $186/mo (-22%) |
Принимать такие рекомендации стоит после согласования с финансовым отделом — это долгосрочное обязательство.
3. Kubernetes Infrastructure
Заголовок раздела «3. Kubernetes Infrastructure»Рекомендации по worker-нодам кластера (в отличие от Quick wins, которые касаются отдельных pod-ов и workload-ов). Данные приходят из отдельного backend-эндпоинта /recommends/k8s/staged, поэтому секция появилась как самостоятельный блок на странице.
Типы:
| Тип | Когда появляется | Рекомендация |
|---|---|---|
| Unbalanced workers | Нагрузка распределена неравномерно между нодами | Включить Kubernetes Descheduler |
| Scale down | В кластере есть избыточная ёмкость | Убрать underutilized worker-ноды |
| High utilization | Нода перегружена | Managed: включить HPA. On-premise: добавить ноды |
| CPU pressure | Нехватка CPU на ноде | То же, что High utilization — HPA или +ноды |
| Memory pressure | Нехватка памяти | То же |
| Empty workers | Нода без рабочих подов | Убрать пустую ноду |
Таблица:
| Колонка | Смысл |
|---|---|
| Node | Имя ноды + кластер + короткое описание причины |
| Type | Один из 6 типов выше |
| Kind | Managed (для Managed Kubernetes) или On-premise — определяется бэкендом автоматически по имени ноды |
| Priority | high / medium / low |
| Advice | Человекочитаемая рекомендация. Ключевые термины (Kubernetes Descheduler, Horizontal Pod Autoscaler, HPA) — inline-кликабельные ссылки на документацию |
| Potential savings | Экономия в месяц, если backend её оценил. Сейчас для worker-рекомендаций обычно пусто |
| Actions | Только Hide/Show. Resolve для worker-рекомендаций недоступен: они либо «рассасываются» сами при перераспределении подов, либо требуют вмешательства, которое платформа не может детектировать как «решение» |
Статус-фильтр (Active / Hidden / Solved) общий с Quick wins: он управляет сразу обеими таблицами, а счётчики в табах суммируют записи из обоих блоков.
Статусы
Заголовок раздела «Статусы»- Active (N) — новые, учитываются в Potential Savings.
- Solved (N) — резолюция случилась автоматически (ресурс удалён, изменён тип, утилизация нормализовалась).
- Hidden (N) — скрыты вручную. Экономия не учитывается в Active, но сохраняется в общих показателях.
Типовой workflow
Заголовок раздела «Типовой workflow»- Каждый понедельник просматривайте список, фокусируйтесь на
priority = high. - По каждому элементу назначайте ответственного и действие.
- Нерелевантные (compliance-ограничения, не подлежат удалению) — скрывайте.
- По факту выполнения проверяйте, что рекомендация перешла в Solved — это произойдёт автоматически на следующей суточной генерации.
Ограничения
Заголовок раздела «Ограничения»- Рекомендации строятся по истории 3–90 дней (зависит от типа). Для свежих ресурсов рекомендаций не будет.
- Платформа не выполняет действия в облаке за вас — все изменения делаете вы в консоли провайдера или через IaC.
- Оценка экономии для CVoS основана на стабильности потребления: если workload пиковый, реальная экономия может быть ниже.
Таб Anomalies
Заголовок раздела «Таб Anomalies»Таб Anomalies показывает отклонения в работе инфраструктуры и расходах.
Табы и состояния
Заголовок раздела «Табы и состояния»- Active (N) — активные, ещё не решённые.
- Hidden (N) — скрытые вами.
Типы аномалий
Заголовок раздела «Типы аномалий»| Тип | Смысл |
|---|---|
| Sudden spend | Вчерашние расходы облака выше среднего за 7 дней более чем на 10% |
| Usage spike | Резкий рост CPU или памяти ресурса относительно недельной нормы |
| Zombie host | Хост 7 дней подряд с CPU и памятью в нуле |
| Rule violation | Сработало правило из Settings → Rules (например, High Memory Usage) |
Строка аномалии
Заголовок раздела «Строка аномалии»- Дата обнаружения.
- Счётчик повторений за период (
×1383). - Бейдж типа (
Rule Violation,Sudden spend, …). - Описание: имя ресурса, метрика, порог, правило.
- Иконка «скрыть» справа.
Что делать с новой аномалией
Заголовок раздела «Что делать с новой аномалией»- Прочтите описание, откройте карточку ресурса (клик по имени).
- Если аномалия — ложная или плановая (знали заранее), скройте её.
- Если проблема реальная, устраните причину (перезапустите под, поправьте лимиты, удалите ресурс).
- На следующей суточной генерации аномалия автоматически перейдёт в resolved, если условия больше не выполняются.
Когда аномалий слишком много
Заголовок раздела «Когда аномалий слишком много»- Скройте хронические ложные срабатывания.
- Ослабьте пороги в Settings → Rules — уменьшите severity на определённые случаи.
- Настройте Alert Configurations, чтобы важные аномалии приходили в Telegram, а не только были на странице.